
发布日期:2024-07-19 浏览次数:
我当时快速看了一遍,还是挺有价值的一个工作(与moblie aloha、humanplus最大的区别是,moblie aloha是通过从动臂遥控,humanplus则是用过影子系统遥控,而television则是远程遥控,之后机器人再自主操作),一直想做下解读来着
7.11,在和一长沙的朋友聊到我司给工厂的机器人解决方案时,他无意中也发了「Open-TeleVision」这个工作的链接给我,说他也在关注这个团队,并表示:“VR+具身智能,应用场景太大了”
基于模仿学习的机器人在本博客的前几篇机器人文章中已经介绍过很多了,其中有个关键点便是数据的收集
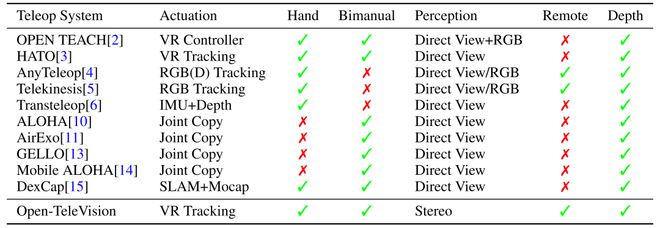
teleoperation framework for robot manipulators] 然而,这要求操作员和机器人必须在同一地点,无法进行远程控制,即每个机器人硬件需要与一个特定的远程操作硬件配对 重要的是,这些系统尚不能操作多指灵巧手(Moblie aloha和UMI确实都没有灵巧手,dexcap才有) 好在,VR头显制造商通常集成内置的手部跟踪算法,这些算法融合了来自多种传感器的数据,包括多个摄像头、深度传感器和IMU。通过VR设备收集的手部跟踪数据通常被认为比自开发的视觉跟踪系统更稳定和准确,而后者仅使用了所提到传感器的一部分(RGB+RGBD[4],Depth + IMU[6]等)
提前说一嘴,总之,在TeleVision之前,没有系统同时提供远程控制和深度感知:操作员在直接观看(需要物理存在)和RGB流(放弃深度信息)之间做出选择。通过利用立体流媒体,TeleVision将首次在单一设置中提供了这两种功能
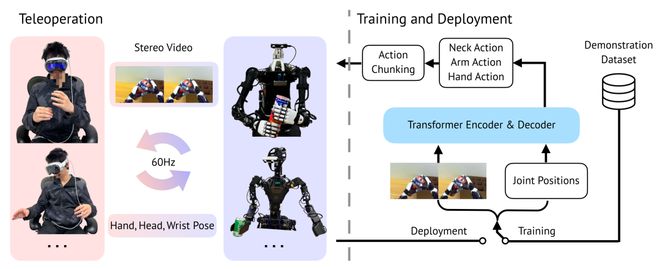
上图左侧:是远程操作系统 首先,爱游戏中国官方网站VR设备(虽然系统对VR设备型号不敏感,但还是选择的Apple VisionPro作为VR设备平台)将的手部、头部和手腕的姿态流式传输到服务器 其次,服务器再将人类姿态重新定向到机器人(用了两个机器人做实验,一个来自宇树科技的具有多手指的Unitree H1,一个则是傅里叶智能的具有抓手的Fourier GR1) 最后,将关节位置目标发送到机器人 换言之,通过捕捉人类操作员的手部姿势,然后进行重新定位以控制多指机器人手或平行爪抓手,最后依靠逆运动学将操作员的手根位置转换为机器人手臂末端执行器的位置
上图右侧:使用基于transformer的动作分块算法即ACT,为每个任务训练模仿策略,比如Transformer编码器捕捉图像和本体感觉token的关系,Transformer输出特定块大小的动作序列
而TeleVision对允许细粒度操作的主要贡献来自感知,它结合了具有主动视觉反馈的VR系统即在机器人头部使用单个主动立体RGB相机,配备2或3个自由度的驱动,模仿人类头部运动以观察大工作空间。在远程操作过程中,摄像头会随着操作员的头部移动而移动,进行流媒体传输,即如下图所示

这是因为实时、自我中心的3D观察传输到VR设备,使得人类操作员看到的是机器人看到的。这种第一人称主动感知为远程操作和策略学习带来了好处
对于远程操作,它为用户提供了一种更直观的机制,通过移动机器人的头部来探索更广阔的视野,并关注重要区域以进行详细交互
对于模仿学习,TeleVision的策略将模仿如何在操作的同时主动移动机器人的头部 与其采用进一步的静态捕获视图作为输入,主动摄像头提供了一种自然的注意机制,专注于下一步操作相关区域并减少需要处理的像素,从而实现平滑、实时和精确的闭环控制
humanplus通过影子系统实现了人类操作员对机器人的实时控制,那TeleVision又是如何做到实时远程遥控的呢

反过来,机器人以每只眼480x640的分辨率流式传输立体视频(整个循环以60 Hz的频率进行)
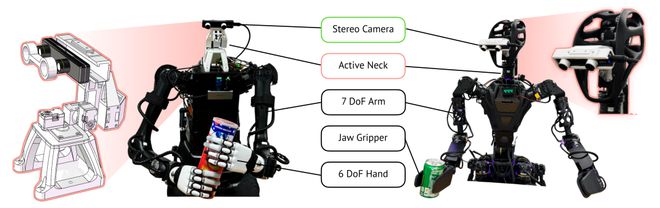
且过程中只考虑它们的主动感知颈部、两个7自由度的手臂和末端执行器,而其他自由度未被使用。其中,H1的每只手有6个自由度 [20],而GR-1有一个1自由度的下颚夹持器
此外,为了主动感知,设计了一个具有两个旋转自由度(偏航和俯仰)的云台,安装在H1躯干顶部,该云台由3D打印部件组装而成,并由DYNAMIXEL XL330-M288-T电机驱动 [21]
对于GR-1,使用了厂家提供的3自由度颈部(偏航、滚动和俯仰),且两个机器人都使用ZED Mini [22] 立体相机提供立体RGB流
对于手臂控制而言,人类手腕姿态首先转换为机器人的坐标系。具体来说,机器人末端执行器与机器人头部之间的相对位置应与人类手腕和头部之间的相对位置相匹配,且机器人的手腕方向与人类手腕的绝对方向对齐,这些方向是在初始化Apple VisionPro手部追踪后端时估计的
这种对末端执行器位置和方向的差异化处理确保了当机器人的头部随人类头部移动时,机器人末端执行器的稳定性
输入的末端执行器姿态使用SE(3)群滤波器进行平滑处理,该滤波器由Pinocchio的 SE(3)插值实现,从而增强了IK算法的稳定性
为了进一步降低IK失败的风险,当手臂的可操作性接近其极限时,加入了关节角度偏移。这种校正过程对末端执行器的跟踪性能影响最小,因为偏移量被投影到机器人手臂雅可比矩阵的零空间,从而在解决约束的同时保持跟踪精度
对于手部控制而言,通过dex-retargeting,一个高度通用且计算速度快的运动重定向库,人手关键点被转换为机器人关节角度命令 [Anyteleop]
TeleVision的方法在灵巧手和夹持器形态上都使用了向量优化器。向量优化器将重定向问题表述为一个优化问题 [Anyteleop, Dexpilot],而优化是基于用户选择的向量定义的:
参数 α是一个缩放因子,用于考虑人手和机器人手之间的尺寸差异(将其设置为1.1用于Inspire手)
参数 β权衡了确保连续步骤之间时间一致性的惩罚项。优化是使用顺序最小二乘二次规划(SLSQP)算法[27]在NLopt库[28]中实时进行的,正向运动学及其导数的计算在Pinocchio[24]中进行
对于夹持器,优化是使用一个单一向量实现的,该向量定义在人类拇指和食指指尖之间。这个向量与夹爪上下端之间的相对位置,使得通过简单地捏住操作员的食指和拇指,可以直观地控制夹爪的开合动作
TeleVision和Moblie Aloha一样,选择 ACT[10]作为的模仿学习算法
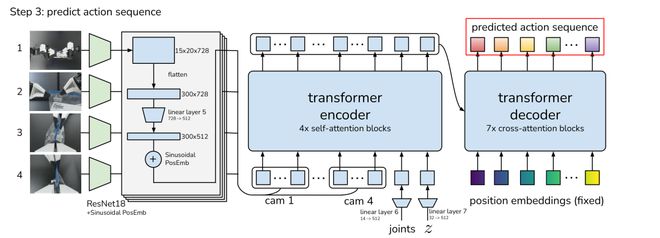
其次,使用两幅立体图像而不是四幅单独排列的 RGB 摄像机图像作为transformer编码器的输入 DinoV2 骨干为每张图像生成 16 × 22个token。状态token是从机器人的当前关节位置投影出来的,且使用绝对关节位置作为动作空间 对于 H1,动作维度是 28(每个手臂 7 个,每只手 6 个,主动颈部 2 个); 对于GR-1,动作维度是19(每只手臂7个,每个夹爪1个,主动颈部3个) 至于本体感觉token是从相应的关节位置读数投影出来的
用于训练ACT [10] 模型的超参数详见下图(虽然这些超参数在所有基线和所有任务中大多数是一致的,但也有一些例外,包括块大小和时间加权)

提前说一嘴,在所有任务中TeleVision使用60的块大小,除了罐插入任务中,TeleVision使用100的块大小。在TeleVision的设置中使用60的块大小有效地为机器人提供了大约一秒的记忆,与推理和动作频率60Hz相对应
尽管如此,我们注意到在罐插入任务中,使用更大的块大小(对应于包含更多的历史动作)对模型执行正确的动作序列是有利的
此外,在原始ACT论文[即Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,详见此文的2.1.1节动作分块:将同一时间步内的预测动作进行聚合]中采用指数加权方案为不同时间步的动作分配权重其中, 是最早动作的权重,遵循ACT的设置。 是上图中提到的时间加权超参数。随着 的减少,更多的强调放在最近的动作上,使模型响应性更好但稳定性较差经过实验发现,对于大多数任务,使用时间权重 m为0.01可以在响应性和稳定性之间达到令人满意的平衡。然而,对于卸载和罐子分类任务,我们调整了这个参数以满足它们的特定需求对于卸载任务, m设置为0.05,确保在手中传递时更大的稳定性对于罐子分类任务, m设置为0.005,提供更快的动作
限于篇幅更到这里爱游戏ayx,想看完整内容私苏苏老师:julyedukefu008或七月在线其他老师领。剩余内容目录如下:

「大模型项目开发线上营 第二期」不止新学员青睐,大模型第一期学员大多数都续报了第二期。商用项目果然受用
一方面,即便在大厂,虽有技术但没法讲其内部项目,而专门搞应用开发的小厂,很难将其赖之生存的项目拿出来讲
二方面,一般职业讲师 背后没有项目团队 只能搞个demo,至于一般教育机构也很难再搞个项目团队,成本大 招人难 做出成果更难
而我司教育团队外,爱游戏中国官方网站我司去年专门成立了大模型项目开发团队(由我带全职和在大厂的兼职组成),且从「教育为主」,逐步转型到了「科技为主 教育为辅」”
现在报名加送:① 一年GPU,封装了诸如ChatGLM3等各大主流大模型② 一个VIP年卡「200多个AI小课、5个大模型小课(即ChatGPT原理、类ChatGPT微调实战、SD及其二次开发、垂直大模型实战爱游戏ayx、大模型数据处理实战)」
服务热线